
COCA, or the Corpus of Contemporary American English, is one of the largest and most frequently used language corpora by researchers, writers, linguistics students, and content creators who want to understand how English is used in real life. Rather than providing rigid definitions, COCA presents millions of examples of words and phrases used in authentic contexts—not estimates, not predictions, but actual language data.
For many, COCA feels like a window into a new way of thinking about language. It helps us see patterns, native speaker habits, and the development of meanings that can’t be captured simply from a dictionary. That’s why COCA is an essential tool for anyone who wants to write more naturally, learn faster, or research language more accurately.
In this guide, we’ll break COCA down into easy-to-understand pieces. No linguistics background or technical experience is required. All you need is curiosity—and from there, we’ll explore step-by-step how COCA works, what its benefits are, and how to use it to improve your English.
What Is COCA?
COCA, or the Corpus of Contemporary American English, is one of the most widely used linguistic resources in the world. It serves as a massive, continuously updated database of real-life English taken from a broad mix of contexts—spoken language, literature, news articles, academic journals, and more. Instead of showing definitions like a traditional dictionary, COCA shows how English is actually used by millions of speakers and writers across different domains.
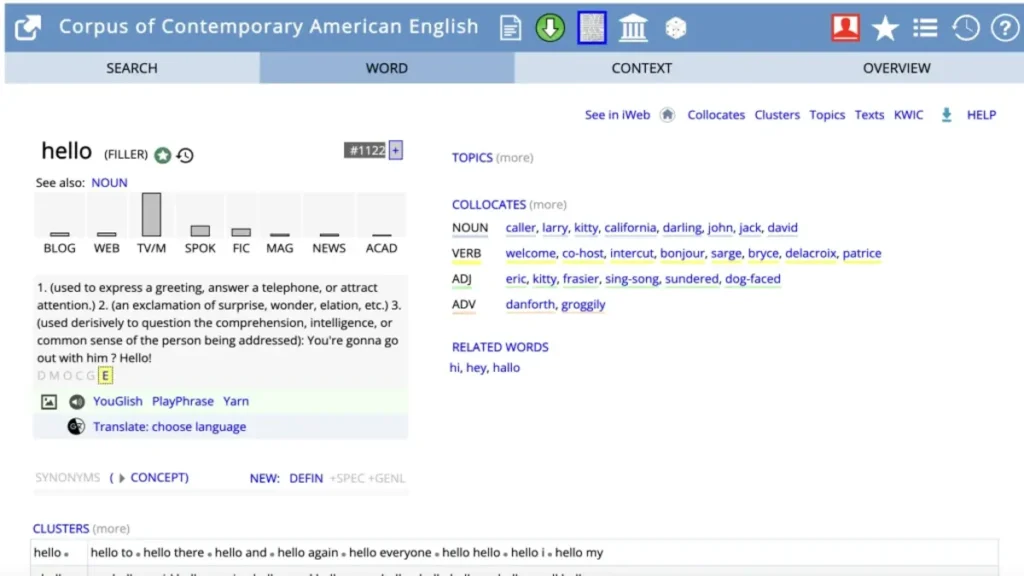
COCA is especially valuable because it helps learners and researchers see authentic patterns in English: which words appear together naturally, how meanings shift depending on context, and how the language evolves over time. It is not just a tool for linguists; students, teachers, editors, and digital creators also rely on it to write more naturally and understand English at a deeper level.
1. A Brief Definition
COCA is a large, genre-balanced corpus containing more than one billion words from American English sources. Each entry in the corpus is taken from real published or spoken content, making COCA one of the most reliable references for studying language patterns.
2. A Short History of COCA
COCA was created by Mark Davies, a linguistics professor who specialises in building large corpora for public use. When the first version launched in 2008, it already stood out because it was freely accessible and regularly updated—two things that were rare for corpora of its size. Over the years, COCA has expanded significantly, gaining millions of new words and additional registers that make the data more representative of modern American English.
3. How COCA Differs from Dictionaries and Other Language Tools
A dictionary gives you definitions. A grammar book gives you rules. COCA gives you real usage.
It shows:
- which words frequently go together (collocations)
- how a word behaves in different registers (spoken vs academic vs fiction)
- examples of real sentences instead of simplified textbook examples
- changes in frequency over time
This makes COCA not just a reference, but a window into the living, breathing form of English that people use every day.
How COCA Is Collected and Updated
COCA’s strength comes from how carefully it is built. Every text inside the corpus is selected, processed, and organised to represent real American English as it is used today. Unlike random text scraping—which often produces noisy or unreliable data—COCA follows clear standards to ensure that its content remains balanced, trustworthy, and modern.
To keep the corpus relevant, new materials are added regularly from many different sources. These updates reflect changes in culture, media, and communication habits. As American English evolves, COCA evolves with it—making it one of the few corpora that truly captures contemporary language use year after year.
1. Balanced Sources Across Multiple Registers
COCA does not rely on one type of text. Instead, it pulls content from a wide set of registers so users can compare language across different contexts. These include:
- Spoken Language: Transcripts from TV, radio, podcasts, interviews, and unscripted conversations.
- Fiction: Novels, short stories, literary magazines, and narrative-driven publications.
- Magazines: Lifestyle, culture, science, history, and general-interest articles.
- Newspapers: Reports, opinions, features, and breaking news across various major outlets.
- Academic Journals: Research papers, scholarly articles, and subject-specific publications.
- Web Content: Carefully curated online text that reflects modern digital communication.
This mixture is intentional—it allows COCA to reflect not just formal English but also everyday language used by millions of people.
2. Annual Updates and Expansion
COCA is not a static dataset. It is updated regularly to include new topics, trends, and linguistic shifts. Modern expressions, emerging terminology, and changes in public discourse are captured through these updates. This makes COCA especially valuable for anyone interested in current language rather than historical patterns.
3. Quality Control and Data Cleaning
Before any text enters COCA, it undergoes several layers of processing. Metadata is added (such as year, genre, and source), formatting is standardised, and non-linguistic elements—ads, scripts, technical markup—are removed. The result is a clean, searchable corpus that offers accurate insights instead of cluttered or misleading data.
COCA’s Structure and Key Features
COCA is more than just a large collection of texts — it is a carefully engineered linguistic tool. Its structure allows users to search patterns precisely, compare language across time, and examine how words behave in real-life contexts. Because every text in COCA is tagged, organised, and indexed, users can move from broad observations to detailed linguistic evidence with just a few clicks.
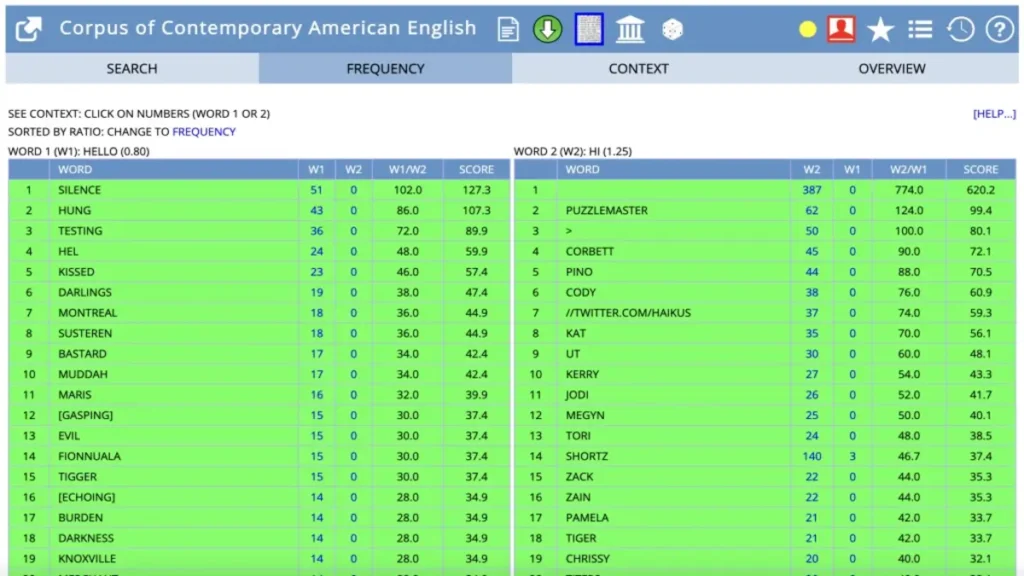
What makes COCA especially powerful is the way it combines massive data with intuitive search functions. Whether you’re exploring how a word is used in speech versus academic writing, or tracking how a phrase has changed meaning over two decades, COCA provides the structure needed to uncover these insights.
1. Part-of-Speech (POS) Tagging
Every word in COCA is tagged with its grammatical category. This means users can filter, compare, and analyse patterns with precision. POS tagging allows searches such as:
- finding verbs followed by specific nouns,
- identifying adjectives commonly used with a certain word,
- analyzing grammatical structures across genres.
This level of tagging transforms COCA from a simple text archive into a detailed linguistic map.
2. Advanced Search Functions
COCA offers several search modes, each designed for a different purpose. Users can explore:
- Keyword searches to examine frequency and usage,
- Concordance lines to see how words appear in full context,
- Collocations to identify words that commonly appear together,
- Phrase-level searches to explore grammar or multi-word patterns,
- Genre comparisons to track differences across spoken, academic, and journalistic language.
These tools help users move beyond guessing and instead base their conclusions on real, measurable language evidence.
3. Chronological Tracking and Trend Analysis
Because COCA includes materials from different years, users can study how language changes over time. This feature makes it possible to:
- observe the rise of new expressions,
- see how certain words fade out of use,
- track cultural or political shifts reflected in language.
Trend analysis is one of COCA’s most valuable strengths, especially for researchers who focus on contemporary language evolution.
Key Features of COCA You Need to Know
COCA is more than just a collection of words; it comes with powerful features that make language analysis accurate and practical. Understanding these features will help you get the most out of COCA.
1. Search by Word / Lemma
This feature lets you search for a word in its base form (lemma) or its variations (e.g., run, runs, running, ran). This way, you can see all the contexts a word appears in without searching for each form separately.
Practical example:
Searching for run shows all its forms, helping you understand overall usage patterns of the word.
2. Collocations: Finding Natural Word Combinations
Collocations are words that frequently appear together in natural contexts. This feature helps you discover which words “fit” together in authentic English.
Practical example:
The word strong often appears with coffee, argument, or relationship. Knowing collocations is useful for writers and content creators to make text sound natural.
3. KWIC (Key Word in Context) and Why It’s Powerful
KWIC displays your target word in the center and shows surrounding words from the original sentences. This helps you understand the word’s context, not just its definition.
Practical example:
If you search for make, KWIC shows phrases like make a decision, make money, or make friends, helping you see subtle differences in meaning depending on context.
4. Register Comparison (Spoken vs Academic vs Fiction, etc.)
This feature allows you to compare how a word or phrase is used in different types of texts: everyday conversation, academic papers, fiction, or magazines. It helps identify the right tone or style for specific contexts.
Practical example:
Children is more common in spoken language and fiction, while offspring is found more in academic writing.
5. Frequency Data and Word Usage Over Time
COCA provides frequency data, including trends over the years. This feature helps writers, researchers, or SEO specialists understand word popularity and language evolution.
Practical example:
Internet usage has risen sharply since the 1990s, while telegraph has declined. This data is valuable for linguistic research or adapting content to modern usage.
How to Use COCA for Beginners
Exploring COCA for the first time can feel challenging, especially if you are new to English corpora or trying to understand authentic language patterns. This section serves as a practical guide, helping you navigate COCA step by step. By following this guide to English corpora, you can start analyzing real English usage and develop insights beyond what standard dictionaries provide.
1. Creating an Account and Logging In
Before accessing COCA fully, creating an account is essential. Without it, some features of this linguistic corpus remain limited, and you won’t be able to save searches or track your findings.
Steps to get started:
- Visit COCA website.
- Click Register or Login at the top right.
- Fill in your details and confirm your email.
Once logged in, you can explore COCA collocations, KWIC examples, and frequency data across various registers. Having an account allows you to fully utilize COCA, making it easier to apply this English corpora hub for writing, language learning, or research projects.
2. Searching for Your First Word
Searching for your first keyword is where COCA truly shows its value. You can examine real-world examples of word usage across spoken, written, and academic English.
To perform a search:
- Type a word in the search bar (e.g., make).
- Choose whether to search by word, lemma, or part of speech.
- Click Search to view results.
This allows you to observe patterns of authentic English in context. For learners and writers, it’s an effective way to explore language through a guide English corpora approach, seeing how words behave in natural communication rather than relying only on grammar rules.
3. Understanding Search Results
COCA provides several tools to help you analyze results:
- KWIC (Key Word in Context): Shows the keyword in full sentence examples.
- Collocations: Highlights words that frequently appear alongside your keyword.
- Frequency Data: Shows how often a word appears across different registers.
Looking at multiple examples rather than a single instance gives a fuller picture of authentic usage. This method reflects the principles of corpus-based learning promoted in many English corpora hub resources.
4. Tips for Reading KWIC Results
KWIC can seem complex at first. To make it manageable:
- Focus on surrounding words to understand meaning.
- Identify repeated patterns across multiple sentences.
- Use filters to narrow by register: spoken, fiction, academic, or magazine.
By applying these strategies, you will navigate COCA effectively while gaining a practical understanding of English corpora usage.
5. Common Mistakes and How to Avoid Them
Common pitfalls include:
- Relying on a single example: Check multiple instances to see general patterns.
- Ignoring parts of speech: Words like run can be a noun or a verb; context matters.
- Overlooking register differences: A word common in spoken English might be rare in academic texts.
Being aware of these mistakes helps beginners use COCA confidently and apply insights to writing, language learning, or research through a trusted English corpora hub.
Short Case Studies – Analyzing Words with COCA
Practical examples help illustrate how COCA works. In this section, we examine real case studies, showing how to analyze words, collocations, and trends. These examples serve as a bridge from theory to practice, making it easier to understand English corpora in action.
1. “Make” vs “Do”
The verbs make and do often confuse learners. Using COCA, you can see real usage patterns and understand context-specific differences.
Searching make shows phrases like make a decision, make money, and make friends, while do appears in expressions like do homework or do the dishes. Observing these patterns in KWIC examples allows learners to internalize usage naturally, illustrating the value of English corpora for authentic learning.
2. Collocations with “Strong”
Collocations show which words frequently appear together. Searching strong in COCA reveals combinations such as strong coffee, strong argument, and strong relationship.
By studying KWIC examples, learners and writers can understand how words naturally pair in authentic English. This practical insight demonstrates how English corpora hub resources help improve writing and language skills by showing real-world usage patterns.
3. Tracking Word Popularity Over Time
COCA also allows you to track changes in word usage over decades, which is valuable for researchers, writers, and content creators.
For instance, internet shows a steep increase in frequency since the 1990s, reflecting technological growth, while words like telegraph have declined. Observing these trends in English corpora gives a dynamic perspective on language evolution, helping you adapt content and writing for modern audiences.
These case studies show how COCA can be applied to analyze word meaning, context, and usage trends. By exploring these examples, readers can confidently use COCA and other guide English corpora tools for research, learning, and writing with authentic language.
COCA vs Other English Corpora
While COCA is one of the most widely used English corpora, it is not the only resource available for exploring authentic language. Understanding the differences between COCA and other corpora can help you choose the right tool for your needs, whether you are a student, writer, or researcher. This section serves as a practical guide, showing how COCA compares to other prominent corpora in the field of corpus linguistics.
1. COCA vs COHA
The Corpus of Contemporary American English (COCA) focuses on recent language usage, including spoken and written registers from the 1990s to the present. In contrast, the Corpus of Historical American English (COHA) emphasizes language changes over time, covering texts from the 1810s to the 2000s.
Using COCA is ideal if your goal is to study modern English usage, while COHA is better for examining historical trends. This distinction is often highlighted in English corpora hub guides, helping learners and researchers select the right resource for their project.
2. COCA vs NOW Corpus
The NOW (News on the Web) Corpus specializes in current news articles from online sources, updated continuously. COCA, by comparison, provides a broader dataset that includes spoken language, fiction, magazines, newspapers, and academic texts.
If you are interested in real-time language trends, the NOW Corpus is extremely useful. However, for a comprehensive analysis of diverse registers in American English, COCA remains the preferred choice, as recommended in many guide English corpora materials.
3. COCA vs BNC
The British National Corpus (BNC) represents English usage in the United Kingdom, covering both spoken and written language from the late 20th century. COCA focuses on American English, making it more suitable if your research or writing targets US-based English usage.
For learners and content creators comparing US and UK English, consulting both COCA and BNC provides valuable insights into regional differences. Many resources in English corpora hub highlight this approach for advanced language analysis.
4. When to Use COCA
COCA is particularly valuable when you want to:
- Study modern American English in diverse registers.
- Explore collocations, KWIC examples, and frequency data.
- Compare word usage across spoken, academic, and fictional texts.
For historical analysis, real-time news, or British English, other corpora like COHA, NOW, or BNC might be more appropriate. By understanding the strengths of each corpus, learners and researchers can make informed decisions, guided by principles found in comprehensive guide English corpora resources.
Who Should Use COCA?
COCA is a versatile tool that caters to a wide range of users. Understanding who can benefit most from it helps you see its value beyond simple word searches. By exploring this section, you’ll also notice how COCA fits into broader resources like the English corpora hub and other guide English corpora materials.
1. English Learners
For students learning English, COCA provides authentic examples of how words and phrases are used in real contexts. Instead of relying solely on textbook definitions, learners can observe natural English usage across spoken, written, and academic registers. This exposure accelerates vocabulary acquisition and improves fluency, particularly when combined with insights from other English corpora resources.
2. Writers, Editors, and Content Creators
Writers and content creators benefit from COCA by discovering collocations, sentence structures, and authentic phrasing. By consulting COCA, you can ensure your content sounds natural to native speakers. Many professionals use COCA alongside other English corpora hub tools to refine style, tone, and word choice in their writing.
3. Linguistics Researchers
COCA is invaluable for researchers studying language patterns, trends, or changes in usage over time. By analyzing frequency data, KWIC lines, and collocations, linguists can derive data-driven insights that are otherwise difficult to obtain. COCA’s structured approach aligns with methods recommended in guide English corpora literature.
4. English Teachers and Educators
Teachers can use COCA to find real examples of grammar, vocabulary, and idiomatic expressions for classroom activities. This makes lessons more practical and grounded in authentic English usage, complementing traditional textbooks and other English corpora hub references.
Why COCA Matters in the Age of AI
In today’s era of AI and machine learning, COCA’s role is more important than ever. Understanding why COCA matters helps us appreciate the value of human-curated language data in an age dominated by algorithms.
1. COCA as a Source of Real Human Language Data
COCA provides a massive collection of naturally occurring English from multiple registers. This ensures that users are accessing authentic language patterns, not artificially generated sentences. Using COCA alongside AI-driven tools ensures that your content and research remain grounded in real English usage.
2. Why AI Models Need Data Like COCA
Large language models rely heavily on patterns found in real-world text. By studying authentic data from COCA, developers and researchers can refine AI outputs to better match natural language. Additionally, learners and writers can cross-check AI suggestions with COCA examples to maintain accuracy.
3. The Danger of Relying Solely on AI
While AI can generate text quickly, relying solely on it without consulting real-world sources may lead to errors, unnatural phrasing, or outdated usage. COCA provides a reliable reference of human language, allowing users to verify and improve AI-generated content. Combining AI tools with COCA is a practical approach encouraged by many guide English corpora resources.
By integrating COCA into your learning, writing, or research workflow, you gain access to authentic, data-driven insights that AI alone cannot provide. Coupled with other resources in the English corpora hub, COCA ensures your engagement with English remains accurate, natural, and grounded in reality.
Why You Should Start Exploring COCA Today
COCA offers a unique opportunity to engage with English in its most authentic forms. Throughout this guide, we’ve explored how COCA helps learners, writers, researchers, and educators access real-world English patterns, analyze collocations, and track changes in language over time.

By using COCA, you’re not just memorizing vocabulary or grammar rules—you’re observing how words and phrases function naturally across spoken, written, and academic contexts. This makes your learning, writing, or research more accurate, relevant, and meaningful.
Exploring COCA also connects you to a broader ecosystem of English corpora resources, including guides and hubs that provide additional insights into authentic language usage. By incorporating COCA into your workflow, you develop a deeper understanding of English and strengthen your ability to produce content that reflects real-world usage.
So, whether you are a student aiming to improve fluency, a writer seeking natural phrasing, or a researcher analyzing language trends, now is the perfect time to start exploring COCA. Begin with a simple search, examine KWIC lines, and explore collocations—you’ll quickly discover how empowering it is to interact with authentic English data.
Leave a Reply